Analysis of Miners
The mining structure and mining model are separate objects. The mining structure stores information that defines the data source. A mining model stores information derived from statistical processing of the data, such as the patterns found as a result of analysis. A mining model is empty until the data provided by the mining structure has been processed and analyzed. After a mining model has been processed, it contains metadata, results, and bindings back to the mining structure. The metadata specifies the name of the model and the server where it is stored, as well as a definition of the model, including the columns from the mining structure that were used in building the model, the definitions of any filters that were applied when processing the model, and the algorithm that was used to analyze the data.
All these choices-the data columns and their data types, filters, and algorithm-have a powerful influence on the results of analysis. Each model type creates different set of patterns, itemsets, rules, or formulas, which you can use for making predictions. Generally each algorithm analyses the data in a different way, so the content of the resulting model is also organized in different structures. In one type of model, the data and patterns might be grouped in clusters ; in another type of model, data might be organized into trees, branches, and the rules that divide and define them.
The model is also affected by the data that you train it on: However, the actual data is not stored in the model-only summary statistics are stored, with the actual data residing in the mining structure. If you have created filters on the data when you trained the model, the filter definitions are saved with the model object as well. The model does contain a set of bindings, which point back to the data cached in the mining structure. If the data has been cached in the structure and has not been cleared after processing, these bindings enable you to drill through from the results to the cases that support the results.
However, the actual data is stored in the structure cache, not in the model. Choose the columns from the structure to use in the model, and specify how they should be used-which column contains the outcome you want to predict, which columns are for input only, and so forth. The Data Mining Wizard helps you create a structure and related mining model. This is the easiest method to use. The wizard automatically creates the required mining structure and helps you with the configuration of the important settings. The required structure is automatically created as part of the process; therefore, you cannot reuse an existing structure with this method.
Use this method if you already know exactly which model you want to create, or if you want to script models. Use this method if you want to experiment with different models that are based on the same data set. For more information, see the following topics:. Each mining model has properties that define the model and its metadata.
Defining Data Mining Models
These include the name, description, the date the model was last processed, permissions on the model, and any filters on the data that is used for training. Each mining model also has properties that are derived from the mining structure, and that describe the columns of data used by the model. If any column used by the model is a nested table, the column can also have a separate filter applied.
Combined with the reality of the coal mine, the structural conversion of the location dimension is shown in Table 2. Structured conversion of the location dimension of coal miner unsafe behavior pan-scene data. Tunneling working face refers to the range of the region where the heading is continuing but the roadway is not permanently supported; the tunneling working site roadway refers to the roadway at the tunneling working site except the tunneling working face.
Behavioral property reflects the category of unsafe coal miner behavior combined with relevant research [ 39 , 40 ], including violation of commands, violation of operation, violation of action and non-violation unsafe behavior. Bp1 represents violation of command, BP2 represents violation of operation, BP3 represents violation of action, and Bp4 represents non-violation unsafe behavior.
Factors such as age [ 41 , 42 ], working age, and physical status at work all affect unsafe behavior [ 22 , 43 ]. This paper only analyzes the three attributes of age, working years, and job type in the individual dimension. According to the division of the property of unsafe behavior and the function, behavioral individuals can be divided into three categories: The structural conversion of the behavioral individual is shown in Table 3.
Structured conversion of the behavioral individual dimension of the unsafe coal miner behavior pan-scene data. Age and working years can be queried in the coal company employee management system. However, the classification of coal mines for job type remains unclear. Thus, the grassroots workers are coded according to job type in Table 4.
REPORT: Mine 2018 – An annual analysis of the global mining industry
The degree dimension is used to reflect the severity of unsafe behavior. Based on the more mature division method of accident classification and hidden risk classification, and the analysis and assessment of the risk [ 44 ], the definition of degree dimension is the level of risk combining the practice of coal mine safety management, which is based on the direct or indirect potential severity of the consequences of unsafe behavior. Thus, the unsafe behavior is divided into five levels: The structural conversion is shown in Table 5. Structured conversion of degree individual dimension of unsafe coal miner behavior pan-scene data.
The unsafe action dimension describes the specific unsafe behavior that may lead to accidents, casualties and environmental disruption. According to the purpose of the action, the unsafe actions are divided into four categories: The structural conversion of unsafe action is shown in Table 6. Structured conversion of the unsafe action dimension of unsafe coal miner behavior pan-scene data.
The specialty dimension is used to represent the work stage and the specialized category of the coal miner when unsafe behavior occurs. The structural conversion of the specialty is shown in Table 7. Structured conversion of the specialty dimension of unsafe coal miner behavior pan-scene data. Before mining accident data, it is necessary to eliminate the heterogeneous nature of the data [ 46 ]. Cluster analysis is used to preliminarily explore the distribution of accidents and to prepare for multi-dimensional correlation analysis.
The use of multi-dimensional interaction analysis in different clusters can deeply explore the interaction relationship between different dimensions, which is of great significance for discovering the potential characteristics of unsafe behavior. According to the eight dimensions of the unsafe coal miner behavior pan-scene data, theoretically, any two or more dimensions can be analyzed.
The interaction between different dimensions has different practical significance, which can explore the deep rules of unsafe behavior and improve safety management efficiency. Some representative dimensions for association analysis and the meaning of safety management are shown in Table 8. The accident investigation reports were used for analysis. This paper selects cases of gas explosion accidents in China [ 47 ]. To ensure the accuracy of the data, this paper follows the principles of accident completeness and case authoritativeness: The completeness refers to the complete content of the accident investigation report and to facts that are expressed clearly to analyze the human factors according to the report content.
Furthermore, authoritativeness refers to the accident report that must be issued by the state-accredited accident investigation or safety regulatory institutions. Because the description of unsafe behavior in the original accident investigation report is in unstructured text records, it must be adjusted to the coal mine unsafe behavioral pan-scene data description model to achieve the structural conversion.
Three coal mine gas explosion accidents were selected as an example, and the results of the description and structural conversion processes are shown in Table 9. The pan-scene data can enable coal mining companies to record the unsafe behavior of workers more accurately and provide a method for evaluating the record for unstructured or semi-structured data on unsafe behavior and a way to analyze and visualize it.
Data mining is a fast and effective way to find unknown, implicit and potentially useful information from large-scale data to guide decision making. It is necessary to select a suitable tool to mine useful information and knowledge with strong application value from a large amount of unsafe behavior data of miners.
As an unsupervised learning method, clustering plays an important role in the data natural grouping structure and has been widely used. In the efficiency of the algorithm and clustering effect, the existing cluster methods have achieved excellent performance. The k-means algorithm has been widely used for many years because of its high efficiency in data processing and good clustering effect in numerical data. However, the k-means algorithm can only evaluate a data set with continuous attributes, and the structured data presented here represent a discrete type dataset that contains many classification attributes.
Thus, the k-modes algorithm is selected, which realizes the high-efficiency of the k-means algorithm while realizing the clustering of the discrete-type data [ 48 ]. In the k-modes algorithm, the difference factor is used to replace the distance in the k-means algorithm, and the smaller the difference factor is, the closer the distance will be. The difference factor between a sample and a cluster center is the number of different attributes: The resulting value is the difference factor between a sample and the corresponding cluster center.
Given a data set Z , each data point is described by n classification variables, and the difference factor between X and Y is calculated as follows:. Association rules are the techniques applied to large-scale database mining. The core of the association rules is to show the rules of association and the correlations between different items, which is an implication of the form: Support, confidence, and lift are three important parameters in the association rules.
The support reflects the strength of the association rules. The minimum support is the minimum support threshold of the itemset, which is denoted SUPmin and represents the minimum importance of the association rules. The association rules with high support and confidence can more clearly illustrate the problem in general.
The minimum confidence is denoted CONFmin. The purpose of association rule mining is to find strong association rules and provide decision making assistance. When the lift exceeds 1, it means that the LHS has a great influence on the RHS , and this association rule has obvious practical significance; in contrast, when the lift is less than 1, it means that the probability of RHS under the condition of LHS influence is smaller than the prior probability, and this association rule has no meaning in reality. Moreover, when the lift equals 1, it means that the leader and the successor are independent, and there is no relationship between them.
In this paper, we use the Apriori algorithm proposed by Agrawal to mine mining association rules from the clustering data set for the unsafe behavior of miners [ 49 ]. The primary problem of clustering analysis is determining the number of clusters formed by clustering algorithms. After trying to divide several models, the data clustering number was determined to be 4. After determining the number of clusters, the k-modes algorithm was used to classify the data sets using R software.
Then, each of the separated clusters was characterized. Brief descriptions of the clusters and their sizes are shown in Table The k-modes clustering method was used to analyze the unsafe behavior data of miners. After detailed analysis of all the classification results, it was found that the eight dimensions describing the unsafe behavior of miners could be effectively used as the main variables of the data gathering class, and there was a significant correlation among the dimensions of the unsafe behavior of the miners.
Selecting the data set of Cluster 1 for association analysis and taking the time and location dimensional association analysis as an example, the statistics for the number of unsafe behaviors at different locations in different months are shown in Figure 2. It is seen from the figure that the number of unsafe behaviors in the tunneling working site and coal face was highest in November.
Additionally, the number of unsafe behaviors in the tunneling working site in March, April, and December was significantly larger than the number that occurred in other locations. Moreover, for the room and airway, the number of unsafe behaviors per month was relatively small compared to the other locations. Therefore, when safety managers conduct behavior interventions, such as behavioral observations, they can determine from this figure the intensity and proportion of the number of unsafe behaviors in different locations at different times.
Two-dimensional analysis of time and location using data from the gas explosion accident investigation report. The most prevalent unsafe behaviors in different dimensions are explored. The results are shown in Table Combining the meaning of the attributes in each dimension, the results of the association analysis of the data are analyzed. This rule indicates that unsafe behavior occurring in November usually includes casually turning the auxiliary ventilating fan on and off.
The confidence rate of this rule is According to this rule, the safety management efficiency can be improved 1. This rule indicates that traced unsafe behavior of gas explosion accidents usually include not evacuating in the case of reduced or stopped air. According to this rule, the efficiency of inspection of this unsafe behavior can be improved 1.
This rule indicates that unsafe behavior at the coal face usually involves not examining the gas concentration at shift time. According to this rule, the efficiency of controlling unsafe behavior can be improved 2. This rule indicates that the most vulnerable unsafe behavior of gas inspectors is blasting without examining the gas concentration. The confidence rate of the rule is According to this rule, the efficiency of targeted safety training for gas inspectors can be improved 2.
This rule indicates that when there is a major risk of unsafe behavior, it usually involves blasting without examining the gas concentration.
According to this rule, the efficiency of controlling unsafe behavior that is of major-risk can be improved 1. This rule indicates that when unsafe behavior occurs during the heading process, it usually involves unqualified hole-sealing. According to this rule, the efficiency of the behavior observation of the tunneling working site can be improved 1. In this paper, the investigation reports of coal mine gas explosion accidents are taken as the data source. Through the theoretical framework of unsafe behavior characteristic analysis based on the pan-scene data, the eight dimensions of time, behavioral trace, location, behavioral property, behavioral individual, degree, unsafe action and specialty are used to describe unsafe behavior, and the data structure conversion is realized.
Through cluster analysis and association analysis, the unsafe behavior characteristics of coal miners are obtained and the guiding significance of the results for coal mine safety management are analyzed. Coal mining remains a high-risk occupation [ 50 ], and coal mine safety data have complex, dynamic and heterogeneous, fuzzy and random characteristics [ 51 ].
Meanwhile, digital and intelligent mine construction propose new requirements for safety management work. Based on this situation, the findings in this paper have significant implications for safety research. The process of describing miner unsafe behavior and constructing structured pan-scene data are conducive to promoting coal enterprises to collect unsafe behavior data and manage safety information resources. In addition, this information can be used to explore the value of existing resources of behavior-based safety.
The application of new technologies and the increased emphasis on safety by the government has resulted in a decrease in the fatality rate of coal mines in China [ 52 , 53 ]. The construction of digital and intelligent mines proposes new requirements for coal mine safety management. The intelligent safety management must pay more attention to the application and mining of data resources. The massive data sources of unsafe behavior contain a wealth of hidden knowledge of rules and laws.
However, due to the lack of extraction of coal mine unsafe behavior data, these knowledge treasures cannot be used to guide safety management. However, the analysis and mining of data primarily focuses on the construction of a data mining model and algorithm and the application of computer technology [ 54 , 55 ]. For the large safety production dataset, these methods are relatively weak, which restricts the extraction of safety data and the improvement of safety management. In response to this type of problem, the description of pan-scene data and the process of data structure conversion in the framework greatly improve the processing capabilities for large datasets and is of great significance to the effective use of information resources and the intelligent management of a coal mine.
For coal mine safety managers, the structured processing of behavior safety data eases the burden on managers in terms of collating photos and records of unsafe behavior. In addition, the statistical analysis and multi-dimensional association analysis results help safety managers to clarify the characteristics and rules of unsafe behavior of workers, which improves the efficiency of safety management and optimizes the allocation of management resources.
The occurrence of unsafe coal miner behavior has intrinsic complexity and is greatly affected by the natural environment, coal mining technology, personality traits, and management level [ 22 ]. Using clustering analysis, the potential rules among the dimensions of unsafe miner behavior can be preliminarily excavated, and the heterogeneity of much unsafe miner behavior data can be effectively eliminated at the same time.
It is of great significance to determine the potential features of unsafe behaviors using association analysis to explore the relationship between the different dimensions in a particular single cluster. The interaction between different dimensions has different meanings.
1. Introduction
Safety managers can select the different dimensions according to their needs and judge whether there is regularity between them through the interaction results to improve the efficiency of safety management and stimulate the advancement of empirical safety management to intelligent safety management. For the workers of coal mining enterprises, the visual presentation of the data analysis results has improved their level of information cognition.
The results of cluster analysis and association analysis of eight dimensions are mostly displayed in visualization, which has characteristics that can be summarized as visibility, interactivity, and multidimensionality. Based on the perspective of safety cognition and the different individual attributes, the results will be provided to the workers to improve their information absorption and analysis ability and their safety behavior selection ability. The theoretical framework for analysis of unsafe behavior characteristics based on pan-scene data in this study has very important application value.
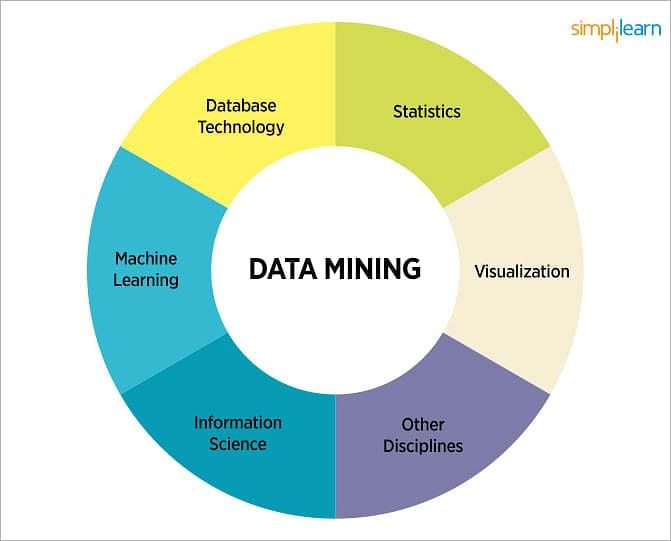
The requirement of the pan-scene data theory to the accident data source can maximize the comprehensive description of human unsafe behavior factors. The accuracy and completeness of unsafe behavior data are guaranteed. Thus, the unsafe behavior information associated with the accident can be extracted more thoroughly. It only covers machine learning. Please expand the section to include this information. Further details may exist on the talk page. Examples of data mining. Data mining and machine learning software. Analytics Behavior informatics Big data Bioinformatics Business intelligence Data analysis Data warehouse Decision support system Domain driven data mining Drug discovery Exploratory data analysis Predictive analytics Web mining.
Data integration Data transformation Electronic discovery Information extraction Information integration Named-entity recognition Profiling information science Psychometrics Social media mining Surveillance capitalism Web scraping. Definition of Data Mining". Data Mining, Inference, and Prediction". Archived from the original on Concepts and Techniques 3rd ed. Retrieved 17 December Data mining in business services. Service Business , 1 3 , Practical Machine Learning Tools and Techniques 3 ed. Journal of Machine Learning Research.
Mining Models (Analysis Services - Data Mining) | Microsoft Docs
The term "data mining" was [added] primarily for marketing reasons. The Review of Economics and Statistics. Data Mining, and Knowledge Discovery: Introduction to Data Mining. Retrieved 30 August Retrieved 27 December Concepts, Models, Methods, and Algorithms. The Knowledge Engineering Review. Journal of Chemical Information and Computer Sciences. Top conferences in data mining". Don't Count on It". Connecting the Dots to Make Sense of Data". Columbia Science and Technology Law Review. Retrieved 16 March Archived June 9, , at the Wayback Machine. Retrieved 14 November Its importance and the need for change in Europe".
Association of European Research Libraries. Institute for Operations Research and the Management Sciences. Data Mining and Knowledge Discovery. Yu " Data mining: Creating the data warehouse. Fact table Early-arriving fact Measure. Dimension table Degenerate Slowly changing. Business intelligence software Reporting software Spreadsheet. Bill Inmon Ralph Kimball. Major fields of computer science. Computer architecture Embedded system Real-time computing Dependability. Network architecture Network protocol Network components Network scheduler Network performance evaluation Network service.
There was a problem providing the content you requested
Interpreter Middleware Virtual machine Operating system Software quality. Programming paradigm Programming language Compiler Domain-specific language Modeling language Software framework Integrated development environment Software configuration management Software library Software repository. Software development process Requirements analysis Software design Software construction Software deployment Software maintenance Programming team Open-source model.
- The Trailsman #307: Montana Marauders.
- Miners - Language, tone and structure;
- Navigation menu;
- REPORT: Mine – An annual analysis of the global mining industry – PwC’s Skills for Australia.
- The Changeup (Men of the Show)?
- Foreign Investment in the Petroleum and Mineral Industries: Case Studies of Investor-Host Country Relations (RFF Global Environment and Development Set).
Model of computation Formal language Automata theory Computational complexity theory Logic Semantics. Algorithm design Analysis of algorithms Algorithmic efficiency Randomized algorithm Computational geometry. Discrete mathematics Probability Statistics Mathematical software Information theory Mathematical analysis Numerical analysis. Database management system Information storage systems Enterprise information system Social information systems Geographic information system Decision support system Process control system Multimedia information system Data mining Digital library Computing platform Digital marketing World Wide Web Information retrieval.
Cryptography Formal methods Security services Intrusion detection system Hardware security Network security Information security Application security.